The Probability Of Near-Term AGI-Like Systems
Published on: 2023-03-26 | permalink
Since I wrote “The State of Machine Learning in 2022,” AI has entered the mainstream. The internet is flooded with content about how GPT-like models will change everything. I hazarded to make predictions in “Next steps?” that now seem embarrassingly conservative in hindsight:
-
More modalities are merged. Outcome => Confirmed.
- We now have text, pictures, sound, 3D models, and more.
-
The Scaling Hypothesis Keeps Holding. Outcome => Confirmed.
- Recent GPT results show that performance keeps increasing as models get more extensive and are trained on more and more data.
-
New companies are emerging. Outcome => Confirmed.
- There is an explosion of funding in Generative AI and applications of GPT models. Several of the companies I listed are now unicorns. Some are even decacorns.
So, where are we now? Most people feel overwhelmed by the rate of progress and struggle to sort through all information. This is an attempt to summarize my view.
I have drastically updated my assumptions about the near-term probability of AGI-like systems
Those who know me know I’ve always been skeptical about hyperbolic claims around AI. I always preferred machine learning over artificial intelligence because AI felt pompous. My understanding of the available technology gave me no reason to think we were close to some sort of human-like intelligence. But I’d rather be correct than consistent. It is fair to call today’s algorithms a form of AI. And maybe even AGI-like. At the very least, I have changed my mind about the possibility of near-term AGI-like systems, and I’m implementing many behavioral updates to align my life with my new view. This process started more than a year ago, but it has only accelerated since.
Defining Artificial General Intelligence (AGI) is a distraction
First of all: Spending time defining “what is human intelligence” and “what is AGI” is a distraction. I get why the question is appealing, and I think it is philosophically interesting. But discussing it isn’t necessary for addressing the progress we have made and the opportunities and challenges that brings. Great physicists will tell you that there is always another level of “why” that will stump them. The challenge is to find questions that we can make meaningful progress on now.
We know, for a fact, that currently available language models can answer questions that make them a viable substitute for humans for a wide range of tasks. So in that sense, we have access to some form of general intelligence. I do not believe it is a form equivalent to the intelligence humans possess, but that’s not important. Defining the tool, and relating it to humans, has no impact on its usefulness. As a society, we must accept that large swaths of human workers are about to become obsolete.
Progress will most likely be faster than we can imagine
There is evidence that AI researchers use feedback loops based on LLVMs to accelerate progress further. The impact of this is hard to predict. Assuming scaling laws keep holding and more funding is directed to training LLVMs, I think it is fair to assume there is a compounding acceleration of progress. That means progress in AI is on an exponential trajectory. Of course, it is possible we will find limitations that result in diminishing marginal returns. But from my perspective, there is a higher expected reward from assuming it will continue accelerating.
As with all new technology, descriptions of progress will be dismissed as hyperbolic. My view that we are at the beginning of an exponential development might sound implausible or grandiose. I empathize with this view. There is good reason to be skeptical. Nevertheless, enough evidence exists to prepare for a world where rapid AI progress leads to transformative AI systems.
You could start to notice in the mid-2010s that LLMs improved. Open AI was founded on the premise that we might get on an exponential trajectory toward AGI. The seeds of progress are training data, computation, and improved algorithms. Of course, it was clear there were many considerable hurdles ahead. Multimodality, logical reasoning, transfer learning across tasks, and long-term memory were all unsolved. But one by one LLVMs are overcoming these hurdles.
The short-term impact of increasingly capable AI systems is underestimated
People tend to be bad at recognizing and acknowledging exponential growth in its early phases. Politics is, ironically, both a slow and a short-term process. Most politicians are currently worried about the price of electricity, inflation, or the war in Ukraine. I get that. That said, we need to act with urgency to prepare for the violent disruption that AI will bring to the labor market. Large groups of people will need to reskill quickly. History shows this has a mostly negative impact on earnings. While I’m optimistic the long-term impact of AI will be positive, we should prepare for the short-term disruption.
The Alignment Problem
I will quote from Anthropic’s website:
We do not know how to train AI systems to robustly behave well. So far, no one knows how to train very powerful AI systems to be robustly helpful, honest, and harmless. Furthermore, rapid AI progress will be disruptive to society and may trigger competitive races that could lead corporations or nations to deploy untrustworthy AI systems. The results of this could be catastrophic, either because AI systems strategically pursue dangerous goals, or because these systems make more innocent mistakes in high-stakes situations.
I think aligning AI systems with human values, and human preferences will be the main activity for both companies and governments for the foreseeable future. There is a new programming paradigm emerging with the advent of LLVMs. It’s already over ten years ago that we moved from programming with code to programming with examples. We are now in the middle of yet another transition: fine-tuning large models based on human feedback. I want to try and explain what I mean by that.
Curating “The Essence of Concepts” in Latent Spaces
My interpretation of LLVMs is that they learn “the Essence of Concepts.” Let me explain. Around 2010 it became clear that with enough labeled data, you can learn almost any task. Construct your dataset, carefully assemble labels, specify a loss function and neural network architecture, train your network, and deploy. This approach has been applied successfully to many tasks for the past decade.
But supervised learning has severe limitations , the most notable of which is the shortage of labeled data. Even with a great Data Engine, such as the one Kognic provides, there won’t be enough labels to learn everything. Geoffrey Hinton is famous for saying:
The brain has about 10^14 synapses and we only live for about 10^9 seconds. So we have a lot more parameters than data. This motivates the idea that we must do a lot of unsupervised learning since the perceptual input, including proprioception, is the only place we can get 10^5 dimensions of constraints per second.
Rather than relying on text explicitly labeled, GPT models learn latent representations by reading large quantities of text. There is a form of supervision involved since humans had to write everything on the internet first, but it is different from explicit labeling targeting a specific task.
Understanding the idea of learning “the Essence of Concepts” requires understanding the inner workings of transformers, attention, and latent spaces. But in short: when we expose LLVMs to large amounts of multi-modal data, a representation is formed to maximize the probability of predicting the next item in a sequence. This representation abstracts away the superficial properties of words, objects, and even sentences. Ultimately, concepts become points in a high-dimensional space.
Models can decode from these points into whatever modality they can access and predict text or render images. Zero-shot translation is an example of this, where each language can be considered a modality. Concepts become points in a shared latent space from which you can decode into any language part of the training process. Even when there is no direct mapping present in the training data.
The surprising thing in recent years has been the extraordinary capacity demonstrated by GPT-style models to learn many different concepts simultaneously. It is from this ability that their power comes. What seems like a magical ability to handle prompts never seen in the training data is most likely because the essence of the concept can be there anyway; we might just not realize it. Humans are bad at thinking about points in high-dimensional spaces, and we cannot encode/decode such concepts. So for us, a concept might be missing in the training data. But for the model, some completely different things in the training data might end up very close to your prompt in the learned latent space. And voila, the model predicts tokens in a way that feels magical.
The consequence is that programming now becomes a matter of curating the concepts encoded in a latent space. We do not have the tools for this as of today. For me, the alignment problem is equivalent to curating the concepts encoded in a latent space. We want to shape concepts to align them with human values and human preferences. That way, model predictions will be acceptable to users.
Learn a Policy from Human Feedback (RLHF) on Latent Spaces
So, how do we align model predictions with human values and preferences? Yann LeCun has been building on Geoffrey Hintons observation about the brain, and in his 2016 NIPS talk, said that:
“If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).”
The battlefield for AI in the coming years, I think, can be found in the intersection between these two ideas: 1) Learn a latent representation by observing a lot of sequences, and 2) Fine-tune model predictions based on learning a policy through reinforcement learning from human feedback (RLHF). This paradigm of RLHF is quickly getting adopted by cutting-edge companies. There’s a great outline of this approach over at 🤗.

In the example from 🤗, humans provide feedback on specific outputs. You prompt the model and then ask a human to rank different answers or suggest improved responses. That feedback is then used to fine-tune your language model. However, implicit in the model is the latent space. This latent space encodes everything the model has seen so that the representation maximizes your ability to predict items in sequences. We have known for a long time that such latent spaces preserve semantic relationships in various ways. Anthropic illustrates a 2D projection of a latent space this way:

By asking humans for feedback, they ascribe human values to sequences that can be grouped in some high-dimensional space. A notable detail is that humans are noisy when asked to assign scalar rewards to outputs directly. Instead, the best way is to ask humans to rank items.
I recently came across an excellent blogpost by Viet Le titled “Building a Defensible Machine Learning Company in the Age of Foundation Models.” He describes what he thinks a defensible flywheel looks like:
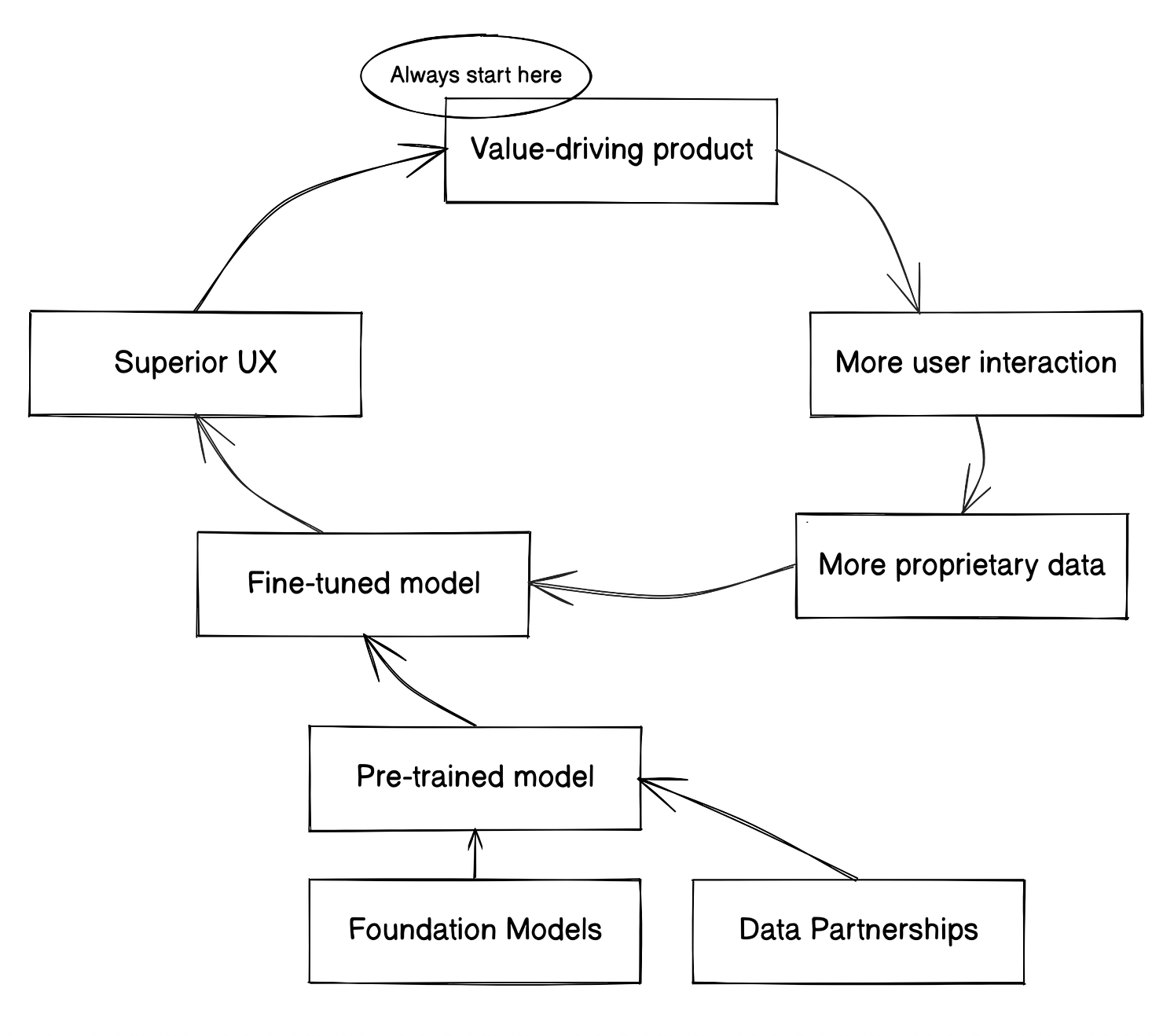
Combine these ideas, and you get a glimpse of the future. I expect we will see larger and larger foundation models trained by large companies and institutions. These Foundation Models will learn from observing large quantities of empirical data. Companies will then create fine-tuned models based on some user interaction. Winners will be companies that can attract the most users that, in turn, generate the best proprietary feedback for your specific application.
To speed up the process, we can apply human feedback directly to the latent space. Rather than have humans look at thousands of examples, we assume that clusters will form in high-dimensional space.

What can the RLHF workflow be applied to?
Anything. Assuming you have enough recorded data in sequences and a ton of computing. Most existing limitations will most likely be overcome with time and money. I expect this is the most viable way to learn how to drive, walk, operate machinery, communicate, and do all the other things humans do. It seems reasonably likely that multi-modal transformers will be enough for many, many applications.
Does this mean AGI is solved?
No. Not even close. While LLVMs are an amazing step towards AGI, there are many, many things that such models cannot solve. I think we will see many novel model architectures in the years ahead and that GPT-styled models are a step on the ladder as opposed to the ultimate solution. But again, that doesn’t mean we shouldn’t embrace them and push them to their limit. It just means there’s a lot more to explore, discover and create.
What’s next?
Well, a lot, probably. But here are some obvious things:
All digital products will have embedded intelligence through integration with some large language model. We are in the middle of the fastest new feature rollout bonanza I’ve ever seen. Since the integration is simple (just an API call to your LLM of choice), anyone can add intelligence to their product in hours.
Great products will require great RLHF solutions. The user experience will need to be tuned. Even with perfect automation, humans have preferences and values that we constantly negotiate socially. Updating behaviors will require efficient ways to fine-tune the concepts encoded in the latent space of your Foundation Model.
A growing constraint will become access to computing resources. These models are still very, very expensive to train. This has been true for a while for the forerunners, but now everyone will start feeling the pain. Expect to spend millions of dollars on GPUs.
Mixed modalities will grow fast. Query and analyze text, video, and sound interchangeably. Store all your company meetings and literally talk to them. This will be a game-changer for business productivity.
Company knowledge bases will be changed forever. Employees will start talking to their companies. I’m assuming they already are, but it will expand rapidly. No more hunting around in some shitty intranet. We will query, using natural language, all documents inside our companies.
As a closing reminder: The future is already here. It is just unevenly distributed. What a time to be alive.